submit date : 16 Aug, 2017
Archive Link
https://arxiv.org/abs/1708.05031
Neural Collaborative Filtering
In recent years, deep neural networks have yielded immense success on speech recognition, computer vision and natural language processing. However, the exploration of deep neural networks on recommender systems has received relatively less scrutiny. In thi
arxiv.org
기계학습 연구실 인턴 2주차에 받은 논문이다. 평소 주변에서 추천시스템 공부를 한다는 말은 많이 들었지만 나는 그동안 딱히 관심이 없었다. 새로운 주제이기도 했고 추천시스템이 뭔지 알 수 있는 좋은 기회였다. 코드 구현 하는 능력도 많이 성장할 수 있었고, (박사님이 분명 쉬운 논문으로 주신다했는데) 처음 접하는 주제라 그런지 조금 헤매서 주변 석사분들께 많이 여쭤보면서 해결해나갈 수 있었다.
코드 구현은 여기를 참고하세요.
https://github.com/ImJaeSung/Neural-Collaborative-Filtering/tree/main
GitHub - ImJaeSung/Neural-Collaborative-Filtering
Contribute to ImJaeSung/Neural-Collaborative-Filtering development by creating an account on GitHub.
github.com
본 논문은 Collaborative Filtering(CF)을 위해 주로 사용되던 Matrix Factorization(MF)방식은 '내적'이라는 너무 단순한 Interaction function을 사용한다는 한계점을 극복하고자 Collaborative Filtering에 Neural Network를 적용한 Neural Collaborative Filtering(NCF)에 대한 연구이다.
기존의 MF방식은 저차원의 선형 공간에서 user와 item간의 Interaction을 표현하기 때문에 새로운 item이 등장했을 때 추가적인 관계를 모델링하고 표현하기에 한계가 있다. 이와 같은 선형적인 한계를 뛰어 넘기 위해 Multi-Layer Perceptron(MLP)구조를 적용하여 user-item interation의 비선형적인 관계 특성을 모델링할 수 있는 프레임을 제안했다.

0. Abstract
Deep neural network가 컴퓨터 비전, 음성인식, NLP 등에서 널리 활약하기 시작하던 그 당시에, 추천시스템 분야에서는 상대적으로 신경망이 덜 부각됐었다. 그나마 있던 연구들도 신경망을 item의 textual description같은 부가적인 정보를 모델링 하는 데만 쓰고 CF의 핵심인 user-item interaction feature에 대해서는 기존의 MF방식을 사용했다. 이런 상황에서 저자들은 MF방법의 고정된 user-item interaction function이었던 '내적'을, 학습 가능한 'MLP 신경망 구조'로 대체하여 성능을 비약적으로 올리는데 성공했다. 이렇듯 MF방식의 CF에서 나아가 신경망을 통해 interaction function 자체를 학습하는 방법을 최초로 도입했다는 데 의의가 있다.
1. Introduction
CF라고 알려진 개인화된 추천시스템의 핵심은 평점, 클릭과 같은 유저들의 과거 interaction들을 기반으로 그 유저들의 상품들에 대한 선호를 모델링하는 것이다. MF가 가장 인기있고 잘 알려진 방법인데, user와 item을 같은 latent space상으로 project하여 latent features를 가지는 vector로 각각 user와 item을 나타낸다. 그리고 한 user의 어떤 item에 대한 interaction은 그 latent vector들의 내적으로 계산한다. 그러나 MF의 이 '내적'만을 사용한 interaction function은 너무 단순하여 성능이 떨어질 수 있다. 실제로 user와 item에 bias term 들을 interaction function에 추가하는 것이 성능의 향상으로 이어진다는 사실이 밝혀졌다. 단순 내적은 user-item interaction의 복잡한 구조를 capture하기에 불충분하다는 것이다. 결국 interaction function을 잘 디자인하는 것이 매우 중요한 문제라는 사실이다.
신경망 혹은 DNN은 임의의 연속함수를 잘 근사할 수 있다는 것이 증명됐고 다른 여러 분야에서 그 효과가 이미 입증되었다. 그러나 당시까지의 추천시스템 연구는 MF 방법에 관해서만 집중하고 신경망을 이용하려는 시도는 상대적으로 적었다. 몇몇 DNN을 이용한 추천시스템 연구도 간접적인 정보(e.g. textual description of items, audio features of musics and visual content of images)의 모델링에만 신경망을 사용할 뿐, 여전히 핵심적인 CF 모델링에 있어서는 MF 방법에 기초하여 단순히 user, item latent features의 내적을 계산했다.
그래서 이 연구에서는 신경망을 통해 CF에 접근한다. content provider의 입장에서 수집하기 쉬운 implicit feedback(e.g. watch, click, purchase)만 다뤘다. 이런 implicit feedback은 간접적으로 사용자의 선호를 반영하고 있지만, explicit feedback(e.g. rating, review)과 비교할 때 사용자의 만족이 직접적으로 드러나지 않고 negative feedback이 부족하기 때문에 이용하기 어렵다. 여기서 negative feedback이 부족하다는 것은, 사용자가 어떤 상품을 click하지 않았다는 사실이 그 사용자가 이 상품을 싫어한다고 보장하지 않는다는 것이다. 이 연구에서는 이런 noisy implicit feedback signal을 DNN을 통해 어떻게 이용할 수 있는지 알아본다.
2. Preliminaries
2.2 Matrix Factorization
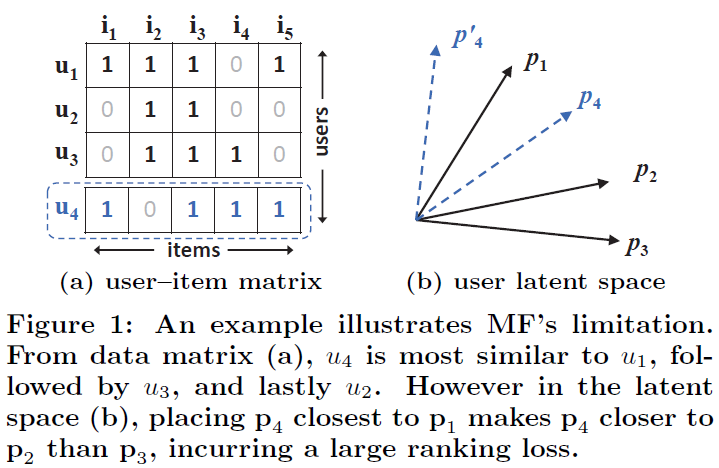
MF를 통해 user를 latent space로 잘 대응시켰다고 할 수 있으려면, 임의의 user에 대하여 user-item matrix에서의 원래 user의 다른 user와의 유사도 ranking과 user latent space에서의 다른 user vector와의 유사도 ranking이 일치해야할 것이다. user-item matrix에서는 유사도를 Jaccard similarity를 쓴다고 가정하고, user latent space에서는 cosine similarity를 쓴다고 가정하자. 또한 user latent space는 2차원 공간이며 각 vector는 unit vector라고 가정한다. 그리고 Figure 1에서 user1(u1), user2(u2), user3(u3)가 있었고 각각 p1, p2, p3로 mapping 됐다고 하자.
Jaccard similarity에 의하면 user간의 similarity는 s23 = 0.66 > s12 = 0.5 > s13 = 0.4 이었는데, 새로운 user4(u4)가 추가됐는데 user-item matrix에서는 유사도 랭킹이 s41 = 0.6 > s43 = 0.4 > s42 = 0.2 순서이다. 그런데 이 u4를 latent space에 p4로서 대응시키려고 하니 p4를 어디에 두어도 원래의 유사도 랭킹이 유지되지 않는 문제가 발생했다. 결국 MF에서는 이렇게 어쩔 수 없이 큰 ranking loss가 일어나는 상황이 있을 수 있다는 한계가 있다. 이는 MF가 저차원의 잠재공간에서 inner product라는 고정되고 단순한 interaction function을 사용하여 복잡한 user-interaciton을 추정하려고 했다는 데 기인한다.
물론 이 상황에서는 잠재공간의 차원수를 높여 당장의 문제를 해결할 수 있다. 다만 잠재공간의 차원수를 높이는 것은 오버피팅으로 이어질 수 있고 특히 sparse 데이터라면 더욱 문제가 된다. 그러니 interaction function 자체를 더욱 복잡한 함수로 대체해야 근본적인 해결법이라고 할 수 있을 것이다.
3. Neural Collaborative Filtering
3.1 General Framework

Input one-hot vector -> Embedding layer -> Neural CF layer -> scores로 매우 단순한 구조이다. 학습은 y_hat과 y 사이의 pointwise loss를 최소화하는 것으로 진행한다. Bayesian Personalized Ranking 또는 margin-based loss 같은 pairwise loss로 학습하는 것이 더 낫다는 다른 연구결과가 있지만, 여기서는 신경망 모델링에 집중하므로 그냥 pointwise loss를 썼다고 한다.

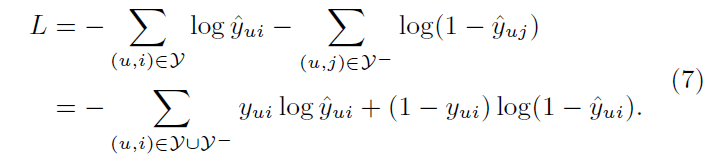
likelihood function은 위의 (6)과 같다. 이 likelihood function을 최대화하는 것은 negative logarithm인 (7)을 최소화하는 것과 동치이다. 결국 우리의 손실함수는 (7)인데 이는 binary cross-entropy loss와 같다. 확률적인 접근을 함으로써 implicit feedback 추천 문제가 이진 분류문제로 바뀐 셈이다. 이때까지는 이 log loss가 분류문제에서만 주로 쓰이고 추천시스템 쪽에서는 거의 사용되지 않았다고 한다. negative sampling은 단순히 각 반복마다 관찰되지 않은 interaction을 uniformly sample했다고 한다.
(item popularity에 기반한 non-uniformly sampling 방법이 더 성능을 높일 수 있지만 pass했다.)
3.2 Generalized Matrix Factorization(GMF)


GMF의 구조는 간단하다. h가 1로만 이루어진 벡터이고 활성화함수 a_out이 identity 함수라면 GMF는 MF 그 자체가 된다. MF는 GMF의 한 특별한 경우로 볼 수 있는 것이다. h와 a_out을 어떻게 설정하냐에 따라 여러 변형된 MF를 만들 수 있다. 이 논문에서는 h를 학습가능한 latent factor들로 보고 a_out은 sigmoid를 사용했다.
3.3 Multi-Layer Perceptron(MLP)

user, item embedding vector를 concatenate해서 함께 고려할 수 있도록 하자는게 핵심이다. 다만 단순히 concatenate만 하면 user, item latent feature 사이의 interaction을 설명하는데 너무 부족할 것이다. 그래서 concatenated vector를 여러 hidden layer를 거치게 하여 만들어진 집약된 형태의 벡터를 갖고 score를 계산하도록 했다. 단순히 element-wise한 곱으로 퉁쳤던 GMF보다는 더 유연하고 비선형성을 갖춘 학습이 가능할 것으로 보인다. 활성화 함수로는 ReLU를 사용했는데, 사실 sigmoid, tanh도 가능은 하다. 하지만 실제 실험 결과 ReLU > tanh >>> sigmoid였다고 한다.
저자가 언급한 각각의 함수를 활성화함수로 사용했을 때 문제점은 다음과 같다.
1) sigmoid: 각 뉴런의 출력을 (0, 1)로 제한하여 성능도 제한될 수 있다. 또한 saturation 문제가 있는데, 각 뉴런의 출력이 매우 작거나 매우 커서 sigmoid 값이 0 또는 1에 가까울 때 local gradient가 너무 작아진다. 결국 역전파가 잘 이루어지지 않게 되어 학습이 멈춘다. 저자는 언급하지 않았지만, sigmoid의 출력은 무조건 양수이므로 역전파시 지그재그 문제가 있다고 알려져 있다. local or global optimum을 향해 직선으로 나아가지 못하고 지그재그로 가중치가 업데이트되어 느린 학습 속도로 이어지는 것이다.
2) tanh: sigmoid보다는 낫다. 하지만 tanh(x) = 2sigmoid(2x) - 1로 tanh는 사실상 sigmoid를 살짝 rescale 했을 뿐이므로 sigmoid의 문제를 약간만 완화한 채로 여전히 갖고 있다.
3) ReLU: non-saturated하다고 증명되었으며 spare activations로 이어지므로 잘 overfitting되지 않으면서도 sparse한 data에 잘 맞다고 한다.
'tower pattern'을 따라서 hidden layer의 출력의 크기를 조절했다. 가장 밑단의 hidden layer가 최대 크기의 hidden output을 갖고 위로 올라가면서 더 작은 크기의 hidden output을 출력하도록 했다는 것이다. 정확히는 순차적으로 절반이 되도록 했다. 이 tower pattern의 정당성은, higher layer로 갈수록 적은 수의 hidden units을 사용함으로써 점점 더욱 abstractive한 feature를 얻으며 학습할 수 있을 것이라는 것에 기초한다.
3.4 Fusion of GMF and MLP(NeuMF)
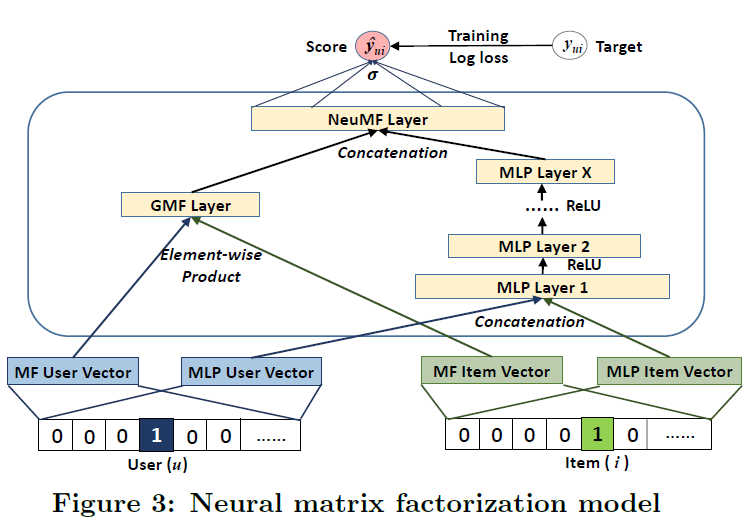

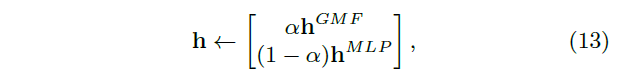
GMF, MLP 각각의 embedding layer가 존재하여 쭉 따로 진행하다가 score를 계산하기 직전에 concatenate하는 구조이다.
embedding 층에서 드는 의문은 '왜 embedding을 공유하지 않는 것일까?' 이다. GMF, MLP 각각의 optimal한 embedding size가 다를 수 있는데 공유해버리면 embedding size가 하나로 fix되므로 좋은 ensemble을 기대하기 어려울 것이라고 한다.
NeuMF는 GMF, MLP를 그대로 합친 것이므로 각각을 먼저 pre-training한 후, 얻은 매개변수를 NeuMF의 초기값으로 사용하여 학습했다. 단, score를 계산할 때 사용하는 h는 GMF, MLP 모두 있으므로 둘 중 하나를 선택하던가 둘을 절충해야 한다. 여기서는 hyperparameter로서 alpha 를 [0, 1]로 설정해서 GMF와 MLP의 h의 가중평균을 NeuMF의 h 초기값으로 설정했다(13) (alpha = 0.5).
GMF, MLP의 학습은 Adam 방법으로 했고, NeuMF는 vanilla SGD를 사용했다. GMF, MLP 각각을 학습시키면서 저장된 Adam의 momentum이 NeuMF에 와서는 무시되므로 또 Adam을 쓰는 것은 적절하지 않기 때문이다.
4. Experiments
RQ1. NCF가 그 당시의 최신 implicit CF 방법을 능가할 수 있는가?
RQ2. 제안한 log loss with negative sampling optimization framework가 추천시스템 task에서 효과가 있는가?
RQ3. user-item interaction 데이터로 학습을 하는 데 깊은 layers가 도움이 되는가?
4.1 Experimental Settings
데이터셋은 MovieLens의 ml-1m dataset과 Pinterest의 dataset을 사용했다.
(전처리 및 train/valid/test set 나누기에 대한 구체적인 내용은 논문을 참고)
Baselines으로는 다음의 네 가지 방법을 정했다.
1. ItemPop: non-personalized. 단순히 item의 interaction수를 기준으로 가장 인기있는 top items 출력
2. ItemKNN: standard item-based collaborative filtering
3. BPR: pairwise ranking loss를 가지고 MF 모델을 optimize
4. eALS: 당시 item recommendation에 대한 MF 최신 기술. optimize squared loss(pointwise loss)
4.2 Performance Comparison (RQ1)

Figure4의 Factors는 NCF의 마지막 layer의 입력 벡터의 차원 수 또는 MF에서 latent vector size를 의미한다. 즉, 몇 개의 factors로 최종 score를 계산할 것인지를 나타낸다.
요컨대 NeuMF가 항상 최고 성능을 보여줬다. 주목할 점은, GMF와 MLP 모두 좋은 성능을 보여줬지만 상대적으로 GMF가 조금 더 우세하다는 것이다. 얼핏 생각하기에 MLP는 더 많은 layer를 갖고 있어서 GMF보다 모델의 복잡도 자체가 훨씬 높기때문에 MLP가 더 우세할 것으로 보인다. 그러나 실제로는 GMF가 더 우세하거나 거의 차이가 없는 것으로 보아, 단순히 user, item embedding vector를 concatenate한 벡터를 다음 레이어에 전달하는 것보다 user, item embedding vector의 내적을 통해 factor-wise한 계산으로 얻은 vector를 전달하는 것이 나을 수 있다. 또한, GMF가 BPR보다 나은 성능을 보여줬는데, 이는 분류 문제뿐 아니라 추천 task에서도 log loss가 쓸만하다는 사실을 보여준다.

한편, Figure 5에서 볼 수 있듯이 ItemKNN이 생각보다 성능이 나쁘지 않다. 시간복잡도가 매우 큰 단순한 방법이지만 나름 놀랍다. 그리고 ItemPop은 예상대로 개인화가 전혀 안되어 있기 때문에 성능이 형편없이 나왔다. 제대로 된 추천시스템이라면 당연하게도 user의 개인화된 선호를 모델링할 수 있어야 한다.
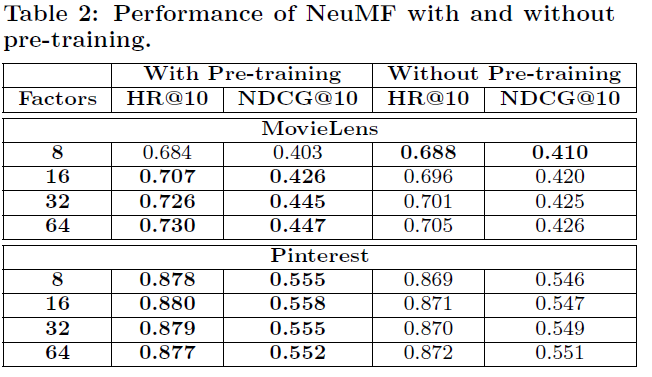
Factors가 너무 작은 경우를 제외하면 이미 학습된 GMF, MLP의 매개변수를 NeuMF의 초기값으로 사용하는게 유의미한 성능 향상을 보였다. 즉, Pre-training은 유의미하다.
4.3 Log Loss with Negative Sampling (RQ2)


Figure 6에서 알 수 있듯이 학습이 진행됨에 따라 loss가 꾸준히 감소하면서 성능도 올라갔다. implicit data에 대하여 log loss를 Loss로서 사용해도 괜찮다는 것이다. 저자의 설명에 따르면, pairsewise한 목적함수와 비교해 이런 pointwise한 log loss의 장점은 negative sampling에 대한 sampling ratio를 유연하게 조정할 수 있다는 데 있다. 실제로 pairwise objective function은 하나의 positive instance에 대해 하나의 negative instance만 sampling할 수 있다. 하지만 pointwise loss에서는 negative sampling ratio에 제한이 없다. 그러니 여러 ratio를 테스트해보고 최적의 ratio를 선택해서 사용하면 된다. Figure 7에서 BPR과 비교하여 이를 확인할 수 있다. 한편, 과한 sampling ratio는 오히려 성능을 떨어뜨릴 수 있다는 것에 주의하자.
4.4 Is Deep Learning Helpful? (RQ3)

Table3는 MLP의 hiden layer 층을 높게 쌓는 것이 더 좋은지에 대한 실험 결과이다. 표에서 보듯 층이 깊을수록 성능이 더 좋다는 결과를 볼 수 있다. 층을 더 쌓다보면 성능이 떨어지는 순간이 오겠지만, 어쨌든 CF에서 층이 깊은 모델을 사용하는 것이 유의미하다는 것을 보여준다. 저자의 설명대로 비선형적인 layer가 쌓임에 따라 더 높은 수준의 비선형성을 갖출 수 있었기 때문으로 보인다.
실제로 activation function으로 ReLU 대신 Identity를 써봤더니 성능이 훨씬 떨어졌다고 한다. 또한 hidden layer가 없는 MLP-0의 경우 ItemPop 수준의 성능이 나왔다. 이는 단순히 user, item latent vector를 concatenate하는 것으로는 부족하고, 은닉층을 통해 적절히 transforming하는 과정이 필수적이라는 사실을 보여준다.
6. Conclusion
본 연구에서는 Collaborative Filtering을 위한 신경망 구조에 대해 탐구했다. NCF라는 일반화된 framework를 고안하면서 그것의 세 인스턴스 GMF, MLP, NeuMF를 제안했다. 이들은 user-tiem interaction들을 서로 다른 방법으로 모델링했다. 제안한 framework가 간단하면서도 일반적이기 때문에, 추천시스템에 관한 딥러닝 접근을 시도할 때 어디든 사용될 수 있을 것이다. CF에 대한 주류의 얕은 모델을 보완하면서 딥러닝 기반 추천시스템 연구의 새로운 가능성을 열었다.
'Deep Learning > Recommend System' 카테고리의 다른 글
| [Recommend System] NDCG 이해하기 (1) | 2023.09.21 |
|---|
