Collborative Filtering 논문 리뷰를 마치고, 박사님께서 정리해보라는 중요한 metric이다.
NDCG(Normalized Discounted Cumulated Gain)란 검색 결과나 추천에서 랭킹 성능을 측정하기 위한 지표이다. 검색이나 추천 알고리즘의 성능이 좋은 경우 쿼리나 특정 유저의 아이템의 관련성이 높을수록 높은 순위에, 낮을수록 낮은 순위에 배치된다. 이 때, NDCG는 관련성이 높은 문서가 상위에 추천되는지를 측정한다.
우선 NDCG를 이해하기 위해 Relvance Score, CG, DCG, IDCG 를 간략하게 알아보자.
Relvance Score(rel)
Relvance Score란 사용자가 추천된 각 아이템과 얼마나 관련이 있는지, 즉 선호하는 지를 나타내는 점수이다. 이는 단순히 관련이 있는 없는지 binary한 값으로 나타나기도 하고, 문제에 따라서는 세분화된 값을 가질 수도 있다.
예시를 통해 알아보자.

아이템이 리스트에 있지만 어떠한 액션도 취하지 않은 아이템은 0, 사용자가 클릭은 했지만 구매하지 않은 아이템은 1, 사용자가 사본적이 있다면 2를 부여한다.
Cumulated Gain(CG)
CG란 관련성의 누적 합을 의미하는데, 상위 아이템 p개에 대해서 동일한 비중을 합한 값을 말한다.

위의 수식에서 p는 Top N의 N으로 상위 p개까지의 관련성을 더할 것인지를 결정한다. CG는 p를 정하지 않으면 어떤 알고리즘의 결과이던 똑같은 값이 나오게 되므로 p를 통해 몇 개까지의 관련성을 유효하다고 볼 것인지 결정해야한다.
또한, Top N에 표함된 아이템의 종류가 같으면 더 관련성 있는 아이템이 높은 순위에 있는 모델과 그렇지 않은 모델의 성능이 같게 측정될 수 있다. 즉, 추천 아이템의 순위를 고려하지 않는다.
따라서 이 값을 직접 사용하지 않고, discount를 적용한 DCG를 사용한다.
CG의 예를 보자.
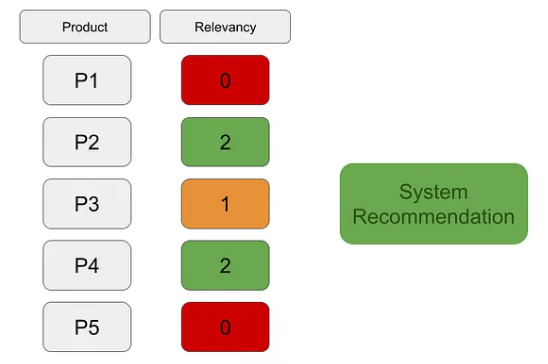
위의 그림에서 CG는 0 + 2 + 1 + 2+ 0 = 5의 값임을 알 수 있다. 더해서, p를 명확히 해주기 위해 CG5라고 쓰기도 한다.
Discounted Cumulative Gain(DCG)
DCG는 기존의 CG에서 랭킹 순서에 따라 점점 비중을 줄여 discounted 된 관련도를 계산하는 방법이다.

위의 식이 standard한 형태이지만,

랭킹의 순서보다 관련성에 더 비중을 두고싶은 경우에는 아래의 식을 사용하여 하위권으로 갈수록 rel대비 작은 DCG값을 가지도록 할 수 있다. 하위권에 penalty를 부여하는 방식이라고 생각하면 이해가 빠를 것 같다. Relevance Score가 binary한 값을 가진다면 두 식을 동치이다.
이외에도 특정순위까지는 discount를 하지 않는 방법 등의 다양한 변형식을 사용하기도 한다.
Ideal Discounted Cumulative Gain(IDCG)
IDCG는 전체 p개의 결과 중 가질 수 있는 가장 큰 DCG값으로, DCG 결과의 가장 이상적인 값을 말한다. 구체적으로 IDCG는 Relvance Score가 큰 순서대로 재배열한 후 상위 p개를 선택하여 DCG를 구하면 된다. 이는 이번 피드의 주제인 NDCG 값을 구할 때 이를 사용하게 되는데, 모델과 직접 관련없이 관련성에 대해서 절대적이라는 특징을 지닌다.


Normalized Discounted Cumulated Gain (NDCG)
NDCG는 정규화 된 DCG를 가리킨다.
기존의 DCG는 랭킹 결과의 길이인 p에 따라 값의 변화가 크다. 따라서 p에 상관없이 일정 스케일의 값을 가지도록 정규화하는 것이 필요하다. 여기서 정규화한다는 것은 모델의 랭킹에 대한 DCG를 IDCG로 나누어 0과 1사이의 값으로 나타낸다는 것을 뜻한다.

평가하려는 추천시스템의 DCG가 IDCG와 같으면 NDCG는 1, rel이 모두 0 이면 NDCG는 0이 된다. 따라서 1과 가까울수록 우수한 추천시스템을 의미한다.
이제 NDCG의 단점에 대해서도 알아보자.
먼저, NDCG는 관련없는 추천에 대한 패널티가 없다는 점이다. 다음의 예를 통해 이해해볼 수 있다.

Set1은 관련 없는 추천 아이템을 포함하지 않으므로 더 나은 집합이나 NDCG의 값은 동일하게 도출된다.
두번째로, 누락된 아이템에 대한 패널티가 없다는 점이다.

위의 예시를 보면 Set2는 관련성이 더 높은 아이템들을 포함하나 NDCG의 값을 동일하다.
다음은 python으로 구현한 NDCG 이다.
import numpy as np
import torch
def NDCG(get_item, pred_item):
if get_item in pred_item:
idx = pred_item.index(get_item)
return np.reciprocal(np.log2(idx + 2))
return 0
def metrics(model, test_loader, top_k, device):
NDCGs = []
for user, item, _ in test_loader:
user = user.to(device)
item = item.to(device)
preds = model(user, item)
# top k choice, value and index
_, idx = torch.topk(preds, top_k)
recommends = torch.take(item, idx).cpu().numpy().tolist()
get_item = item[0].item()
NDCGs.append(NDCG(get_item, recommends))
return np.mean(NDCGs)
'Deep Learning > Recommend System' 카테고리의 다른 글
| [Recommend System] Neural Collaborative Filtering (0) | 2023.09.21 |
|---|
