Submit date: 1 Sep, 2014
Archive Link
https://arxiv.org/abs/1409.0473
Neural Machine Translation by Jointly Learning to Align and Translate
Neural machine translation is a recently proposed approach to machine translation. Unlike the traditional statistical machine translation, the neural machine translation aims at building a single neural network that can be jointly tuned to maximize the tra
arxiv.org
드디어 Attention이다. 그럼 시작해보자.
2014년 발표된 논문으로 당시 Seq2Seq Machine Translation은 RNN, LSTM, GRU 기반의 Encoder-Decoder 구조가 주를 이루고 있었다.
본 논문은 Encoder-Decoder Machine Translation 구조에서 Input sequence의 특정 부분에 집중할 수 있는 Attention mechanism을 제안한다. 모델이 목표 단어를 생성할 때에 Input sequence의 단어와 그들의 Key를 검색하도록 확장하여, 목표 단어 생성에 관련된 정보에만 집중할 수 있게 했다. 그 결과 긴 sequence에 대해 좋은 성능을 냈으며, Alignment와 Translation이 동시에 학습되어 정확한 번역을 생성할 확률이 높아졌고, 고정된 길이의 벡터로 변환하지 않는 구조로 Long term dependency을 해결할 수 있었다.
💡 Abstract
Encoder-Decoder 구조는 의 순서로 Encoder를 통하여 Input sequence를 고정된 길이의 Context vector로 인코딩한 후, 다시 Decoder를 통하여 Context vector를 번역한 결과를 출력하는 구조이다. 무엇보다 장점은 가변 길이의 Input과 Output에 적용 가능하다는 것이다.
하지만 이러한 장점에도 고정된 길이의 Context vector를 사용하는 부분은 모델의 병목현상(bottleneck)이 발생한다. 모델이 Input sequence의 중요한 정보를 고정된 길이의 벡터로 표현하는 것은 쉬운 일이 아니기 때문이다. 그리고 이러한 문제점은 더욱 긴 sequence에 대해서는 보다 극명하게 나타날 것이다. 생각해보면 길이가 긴 문장을 하나의 Context vector로 게다가 길이가 고정된 형태로 압축되면 소실되는 정보는 많을 수밖에 없을 것이기 때문이다.
이에 본 논문은 고정된 길이의 벡터로 Input sequence를 변환하지 않으며, 모델 스스로 Output과 관련하여 Input sequence의 중요한 정보가 어디에 있는지 탐색하여 선택적으로 집중하게 하는 Attention Mechanism을 제안한다.
직관적인 설명을 위해 Attention 이라는 이름을 사용하지만 논문에 따르면 Alignment model을 도입했다는 것이 더 정확하다. 결국 Alignment model을 통해 입력 문장 중 어떤 위치에 현재 단어를 예측할 때 중요한 정보가 담겨있는지를 알고자 하는 것이 Alignment model이 되는 것이다.
✏️Background: Neural Machine Translation
Review 내용이므로 필요하신분은 더보기를 눌러 읽어보세요!
- Translation은 조건부 확률 p(y|x)가 최대가 되는 y를 찾는 것
- 조건부 확률을 학습하는 Neural Machine Translation은 Encoder와 Decoder로 구성
- Encoder는 가변 길이의 Input sequence를 고정 길이 벡터인 Context vector로 인코딩
- Decoder는 Context vector로부터 가변 길이의 y를 출력
- 새로운 Machine Translation은 기존의 Phase기반의 Translation 성능 대비 state-of-the-art(SOTA)를 달성
RNN Encoder-Decoder
- RNN Encoder-Decoder은 이전 연구에서 제안된 align과 translate를 동시에 학습하는 새로운 아키텍처
- RNN 외에 Convolution 등을 적용할 수도 있음
Encoder
- 시간 t
- Input sequence -> sequence vector
- hidden state
- sequence token과 이전시점의 hidden state를 입력으로 함
- 비선형함수 f 적용
- context vector
- 모든 hidden state에 비선형 함수q 적용
- LSTM의 경우 마지막 hidden state만 전달
Decoder
- 타겟 값의 확률은 이전 시점의 출력 결과들과 Encoder에서 생성한 Context vector를 사용하여 구함
- y = (y1, …, yTx)일 때, RNN을 사용하여 조건부 확률을 구하면
p(y|{y1,⋅⋅⋅,yt−1}, c) = g(yt−1, st, c)
- 조건부 확률은 이전 시점의 출력 yt-1, RNN의 hidden state인 st와 Context vector c에 비선형 함수g 를 적용하여 얻을 수 있음
🔥 Learning to Align and Translate

Encoder : Bidirectional RNN for Annotating Sequences
제안하는 모델은 Encoder에 일반적인 RNN이 아닌 Bidirectional RNN을 사용한다.
① forward RNN f
를 input으로 하여 forward hidden state
② backward RNN
를 input으로 하여 backward hidden state
RNN은 기본적으로 최근의 Input을 강하게 반영하는 경향이 있기 때문에 각각의 주변의 단어에 강한 영향을 받는 hidden state일 것이다.
각각의 단어 에 대한 두개의 hidden state concatenate한 결과인 hidden state 를 구한다.이렇게 구한 h를 Annotation이라고 한다. Annotation에는 이전 단어와 다음 단어의 정보를 모두 가지고 있게된다.
정리해보면 기존에 나온 단어들을 통해서만 hidden state를 구축하는 것이 아닌 앞으로 나올 단어에 대해서도 hidden state를 구축하여 거대한 context vector를 만들게 된다는 것을 의미한다.
(화살표로 방향을 나타내는 대신 ' 기호로 나타낸 점 이해부탁드립니다.)
Decoder : General Description
우선 Attention model의 Decoder는 각각 에 대한 Output 를 를 사용하여 계산한다.
각각 는 RNN의 i-1번째 Output이며, 는 i번째 RNN의 hidden state, ci는 i번째 Context vector로 아래의 식으로 계산된다.
Attention mechanism은 처음에 설명했던 대로 고정된 길이의 벡터를 사용하여 대신, Decoder가 각각의 예측마다 Input sequence의 중요한 부분을 탐색하여 선택, 반영하는데 이러한 역할을 하는 것이 바로 Alignment model 이다. 가 바로 Alignment model을 사용하여 계산되는 Context vector로 계산 과정은 다음과 같다.

우선 Decoder의 i-1 번째 hidden state Encoder의 j번째 단어의 concatenated hidden state 간의 energy(유사도) 를 alignment model 를 통해 모든 단어에 대해 계산한다. 이는 다음 hidden state 와 output 를 계산하기 위한 관점에서의 의 중요도를 반영하게 된다는 것을 의미한다.
본 논문에서는 로 feedforward neural network를 사용하여 다른 파라미터들과 함께 학습되도록 하였다.
그 후, softmax 함수를 통해 각각의 energy에 대한 probability(score) 를 계산한다.
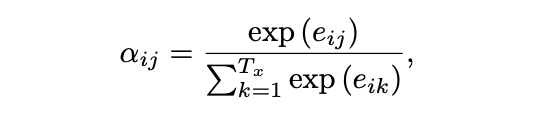
최종적으로, 다음 단어를 Decoding 하기위한 Context vector 는 각각의 단어 들의 를 사용한 가중합으로 계산된다.
Context vector에도 index i가 붙는데 이는 매 단어의 index마다 다시 계산이 수행됨을 알 수 있다.
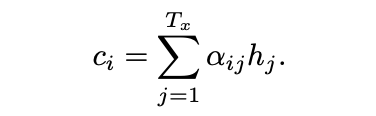
따라서 Context vector 는 고정된 길이 벡터로의 변환 없이 Encoder의 Output sequence 각각에 영향을 받을 수 있게 된다.
Decoder summary

- 일반적인 Encoder-Decoder 구조와 달리 Context vector ci는 각각 에 대한 Output 에 고유한 값
- ci는 Annotation h 값에 의해 결정되며, hi는 Input sequence에서 i번째 단어 주변의 정보를 포함
- ci는 hi들의 가중합으로 계산
- 가중치 값 aij는 softmax로 계산
- 모든 Annotation에 대해 가중합을 하는 것은 모든 가능한 Alignment에 대한 기댓값을 의미
- aij를 Output yi가 xj일 확률이라고 하면 Context vector ci는 모든 annotation에 대한 기대값을 의미
- eij는 Input sequence의 j번째 주변과 Output의 i번째가 얼마나 유사한지에 대한 score
- Alignment model a는 feedforward neural network로 만들어지며, 전통적인 Machine Translation에서와 달리 Latent variable가 아닌 직접적으로 계산
- 다음 hidden state 와 output 를 계산하기 위한 관점에서의 의 중요도를 반영하게 된다는 것을 의미
이러한 메커니즘을 Attention이라고 한다. Decoder에서 Attention을 수행함으로써, Encoder가 Input sequence에 대해 모든 정보를 고정된 크기의 Context Vector에 담아야 되는 부담을 덜어준다.
💡Experimental Results
Datasets
English-to-Franch corpus인 WMT'14를 사용하여 평가하였다. 총 850M개의 단어로 구성되있으나, 348M개의 단어만 추출하여 학습하였다. 토큰화를 통해 가장 빈번하게 사용되는 30,000개의 단어를 선택하여 학습하였고, 포함되지 못한 단어는 [UNK]으로 치환하여 학습하였다. 그 외 전처리나 lowercasing, stemming은 사용하지 않았다.
Models
2가지의 모델을 학습하여 비교하였다. RNN Encoder-Decoder(RNNencdec, Cho et al. 2014a)와 본 논문에서 제안한 모델인 RNNsearch이다. 각 모델은 sentence의 길이를 30으로 제한, 50으로 제한하는 방법 2가지로 학습하였다.
RNNencdec의 Encoder와 Decoder는 각각 1,000개 hidden unit을 가지고 있다. RNNsearch의 Encoder는 forward와 backward 각각 1,000개의 hidden unit을 가지고 있고, Decoder도 1,000개의 hidden unit을 가진다. 각 Target 단어 예측을 위해 single maxout hidden layer를 포함한 multilayer network를 사용한다.
Adadelta를 이용하여 minibatch SGD를 계산하고, minibatch size는 80이다.
학습 후 beam search를 이용하여 최대 확률의 translation을 구하였다.
Results

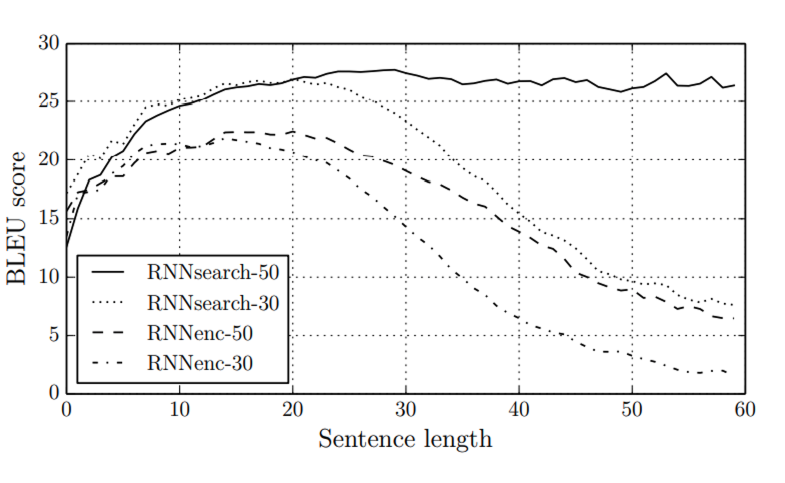
RNNsearch가 RNNencdec의 성능을 능가하였으며, 특히 RNNsearch-50은 긴 문장에서도 성능 하락이 없다는 것을 보여주었다.
Alignment


Annotation weight값 aij의 시각화를 통해 Input sequence의 단어가 Target sequence의 어떤 단어와 연관성이 있는지 알 수 있다.
✏️ 후기
해당 논문은 Encoder-Decoder의 고정된 길이의 Context vector의 문제점을 해결하고자 Alignment model을 도입했다. 이것이 NLP분야에서 Attention이라는 개념의 시작이 되었고, 이후 Transformer 모델의 핵심이 된다. 또한, 이런 Attention은 우리가 어딜 집중해야 하는가를 결정하는 방법론이 된다. 단순히 NLP 뿐만 아니라 CV 분야에서도 Attention 방식을 사용하는 추세이다. CNN의 경우 해당 이미지의 feature를 local하게 구한다면 Attention을 통한 feature extraction은 global하게 구하는 뉘앙스이다. 심지어는 CNN과 attention을 둘 다 활용해서 global-local features를 적절하게 혼합해 구하는 구조도 있는 것 같다. 해당 논문은 최근 주로 사용되는 Transformer에서 사용되는 방식의 Attention은 아니지만 그 영감을 준 논문이기에 중요하다고 판단된다.
이제 transformer 리뷰하자.
Attention is all you need.
Coming soon~
(다양한 어텐션 함수가 등장하였는데, 이 연구와는 어떤 점이 달라졌는지 꼼꼼히 알아보자. self, multi-head, dot 개념..)
'Deep Learning > NLP' 카테고리의 다른 글
| [NLP] DPR: Dense Passage Retrieval for Open-Domain Question Answering (0) | 2024.05.26 |
|---|---|
| [NLP] TF-IDF (Term Frequency - Inverse Document Frequency) 가 (1) | 2023.11.07 |
| [NLP] Attention is All You Need (3) | 2023.09.02 |
| [NLP] Sequence to Sequence Learning with Neural Networks (1) | 2023.08.18 |



